If you’ve read my previous blog posts, you might see a theme: I’ve bought an AIS receiver to pick up ships broadcasts and have been playing with what I can do with the data.
Now I’ve got thinking about how that data is transmitted. AIS receivers make the data available in a standard format via IP or serial connection, and various AIS collection services have leveraged that by providing publicly accessible IPs you can configure directly on your AIS device to sent the traffic their way.
Depending on how much traffic you’re picking up and how what kind of internet connection you have, this might be a negligible amount of your bandwidth, or it might be significant (especially if you’re on a metered connection at sea!) This is compounded if you want to send your data to more than one service, since your device is then sending multiple redundant copies of the same data over the single internet connection.
What’s the solution? One option is compress the data somehow and then send it out to the internet. Since the service won’t know what to do with the compressed data, you’d need an intermediary (perhaps a computer at home, or a server somewhere) that can decompress the data and forward it on.
Before we do anything else though, we need to see how far we can compress and whether it’s worth it!
Compression schemes
When you’re compressing data, you’ve got two main options:
-
Write a custom compressor, using what you know about the data format
-
Use an existing (generic) compression tool, and hope it handles your data reasonably well
As with everything, there are tradeoffs:
With enough advanced knowledge, a custom encoder should be able to produce optimally compressed output, for example using a Huffman Encoding. A generic encoder has to handle lots of different kinds of data, so it’s never going to be optimal.
A widely generic encoder will have had extensive investment in making it as fast as possible, whereas a custom encoder probably won’t have the same investment. On the other hand a generic encoder will do a lot of wasted work trying to find patterns, where a custom encoder will have a much simpler scheme it can run through more quickly.
Custom:
-
Optimal encoding (probably)
-
More efficient code
-
Requires extensive testing
Off the shelf:
-
Variable compression results
-
More optimised code
-
More well tested
We’ll look at writing a custom compressor in the next part, but for now let’s look at using an off-the-shelf compressor.
Enter zstd
There’s a few compression algorithms available (gzip and bzip2 being popular alternatives). zstd is developed by Meta, and has promising benchmark results in their comparison.
More interestingly, zstd provides a ‘training mode’ where you can feed in a load of sample data and generate a ‘dictionary’ file. If both the compressor and de-compressor have access to the same dictionary, you can reduce the amount of storage required to transmit the data as the compressed data can point to entries in the dictionary.
Let’s look at some example data courtesy of AISHub (see below):
!AIVDM,1,1,,A,13HOI:0P0000VOHLCnHQKwvL05Ip,0*23
!AIVDM,1,1,,A,133sVfPP00PD>hRMDH@jNOvN20S8,0*7F
!AIVDM,1,1,,B,100h00PP0@PHFV`Mg5gTH?vNPUIp,0*3B
!AIVDM,1,1,,B,13eaJF0P00Qd388Eew6aagvH85Ip,0*45
!AIVDM,1,1,,A,14eGrSPP00ncMJTO5C6aBwvP2D0?,0*7A
There’s a lot of repetition here, and if we were compressing lots of these strings, then a compressor would spot that AIVDM comes up frequently and deduplicate all the entries. It still needs to output at least one copy, but subsequent instances can just point to the first copy in the file.
If you’re only compressing a string at a time, you lose that opportunity to de-duplicate data:
!AIVDM,1,1,,A,13HOI:0P0000VOHLCnHQKwvL05Ip,0*23
Even though we know it keeps coming up, there’s no way to ‘get across’ the letters ‘AIVDM’ without actually sending it each time. And if each string is being compressed and decompressed independently, that’s eating into our ability to compress effectively.
With the benefit of a shared dictionary, however, we can do much better. The training phase will spot that ‘AIVDM’ keeps coming up, and make sure it’s stored in the dictionary. Then compressing a single line can immediately point to that entry in the dictionary, without explicitly spelling it out. With a large enough dictionary, you’ll probably find longer patterns like ‘1,1,,A’, ‘1,2,,A’, ‘1,2,,B’… all as separate entries in the dictionary, making it possible to collapse that whole section down to a single identifier.
Let’s do some tests!
First we’ll need some training data. AISHub helpfully provides some sample data on this page, which contains ~85K messages (3 minute live AISHub feed). That should be enough to provide a reasonable data set (the zstd tool will helpfully let us know if we aren’t providing enough data for an effective dictionary).
We’ll also need some data to test against. This needs to be different to our training data, otherwise that would be cheating - the dictionary might just happen to store a copy of this section of data, and the ‘compression’ would just be a single pointer to that entry.
Instead I’ll use save data picked up by my own AIS antenna and saved to a file called messages.txt. In this case 7000 lines of it:
wc --lines messages.txt
# 7000
wc --bytes messages.txt
# 334947
Let’s grab and look at the training data. There’s a bit of duplication in the data, so we can use sort -u to filter out unique entries, leaving about 82K lines:
wget https://www.aishub.net/downloads/nmea-sample.zip
unzip nmea-sample.zip
# Archive: nmea-sample.zip
# inflating: nmea-sample
wc -l nmea-sample
# 85194
sort -u nmea-sample | wc -l
# 81863
Now, if we try to just pass the training file to zstd, it’ll complain at us:
zstd --train ./nmea-sample
# ! Warning : some sample(s) are very large
# ! Note that dictionary is only useful for small samples.
# ! As a consequence, only the first 131072 bytes of each sample are loaded
# ! Warning : nb of samples too low for proper processing
# !
# ! Please provide _one file per sample_.
# ! Alternatively, split files into fixed-size blocks representative of samples, with -B# Error 14 : nb of samples too low
Fine, let’s split it up into a temp folder, and pass that instead:
TMPDIR=$(mktemp -d)
split --lines 1 --numeric-suffixes nmea-sample $TMPDIR/nmea-sample.
ls -lrtah $TMPDIR
# total 337M
# drwxrwxrwt 54 root root 12K Aug 15 21:35 ..
# -rw-r--r-- 1 nixos users 49 Aug 15 21:36 nmea-sample.59
# -rw-r--r-- 1 nixos users 49 Aug 15 21:36 nmea-sample.58
# ...
Now we can create our zstd dictionary:
zstd --train -r $TMPDIR
# Trying 5 different sets of parameters
# k=1511
# d=8
# f=20
# steps=4
# split=75
# accel=1
# Save dictionary of size 112640 into file dictionary
First let’s check that zstd can compress and de-compress correctly, both with and without the dictionary:
head -n 1 messages.txt
# !AIVDM,1,1,,B,B3GQeDh00@09il5frI;Q3wuUkP06,0*1C
head -n 1 messages.txt | zstd | unzstd
# !AIVDM,1,1,,B,B3GQeDh00@09il5frI;Q3wuUkP06,0*1C
head -n 1 messages.txt | zstd -D ./dictionary | unzstd -D ./dictionary
# !AIVDM,1,1,,B,B3GQeDh00@09il5frI;Q3wuUkP06,0*1C
We can also see that without the dictionary, the decompression doesn’t work:
head -n 1 messages.txt | zstd -D ./dictionary | unzstd
# /*stdin*\ : Decoding error (36) : Dictionary mismatch
Let’s do some basic compression testing against our messages.txt file:
wc --lines messages.txt
# 7000
wc --bytes messages.txt
# 334947
zstd messages.txt --stdout | wc --bytes
# 80382
zstd -D ./dictionary messages.txt --stdout | wc --bytes
# 80587
As we can see, for a large file the dictionary doesn’t seem to help much - the outputs are within 0.3% of each other. This matches zstd’s guidance here and comment here suggesting that it works best on short strings.
We do see that both massively compress the data, from 328KiB to 79KiB - a 4:1 compression ratio!
So, let’s see about shorter messages. The head tool is useful to taking an initial number of lines from a file.
For a single row:
head -n 1 messages.txt | wc --bytes
# 49
head -n 1 messages.txt | zstd | wc --bytes
# 62
head -n 1 messages.txt | zstd -D dictionary | wc --bytes
# 49
So the dictionary performs better than without a dictionary, but no better than leaving it uncompressed.
At 5 rows, things get better:
head -n 5 messages.txt | wc --bytes
# 245
head -n 5 messages.txt | zstd | wc --bytes
# 192
head -n 5 messages.txt | zstd -D ./dictionary | wc --bytes
# 150
Already we can see a benefit - zstd by itself nets a 22% reduction, while zstd with a dictionary nets a whopping 39% reduction in filesize.
Getting up to 100 lines, we see them get closer again:
head -n 100 messages.txt | wc --bytes
# 4864
head -n 100 messages.txt | zstd | wc --bytes
# 1932
head -n 100 messages.txt | zstd -D ./dictionary | wc --bytes
# 1955
Again they’re within 1% of each other.
So it looks like:
-
if we have too few lines it’s not worth compressing
-
if we have a few lines, it’s worth compressing with a dictionary
-
once the data gets big enough, it’s worth compressing but not worth bothering with a dictionary
Let’s plot this out and work out if we can define some useful cutoffs.
We can write a short script to test with increasing number of lines and generate a CSV with number of lines, uncompressed size, and compressed size with/without a dictionary:
#!/usr/bin/env bash
set -euo pipefail
# delete the file if it exists
rm data.csv || true
# Write the header
echo "lines,uncompressed (bytes), compressed (bytes), compressed with dictionary (bytes)" >> data.csv
# For numbers 1-1000
for ((i=1; i<=1000; i+=1)); do
# Print the number
echo "$i"
# Calculate data for raw, compressed and compressed-with-dictionary
raw="$(head -n $i messages.txt | wc --bytes)"
comp="$(head -n $i messages.txt | zstd | wc --bytes)"
comp_dict="$(head -n $i messages.txt | zstd -D ./dictionary | wc --bytes)"
# Append line to the file
echo "$i,${raw},${comp},${comp_dict}" >> data.csv
done
We can use this CSV to throw together some graphs showing compression ratio and space saving for different numbers of lines (for an explanation of these terms, see this Wikipedia article):
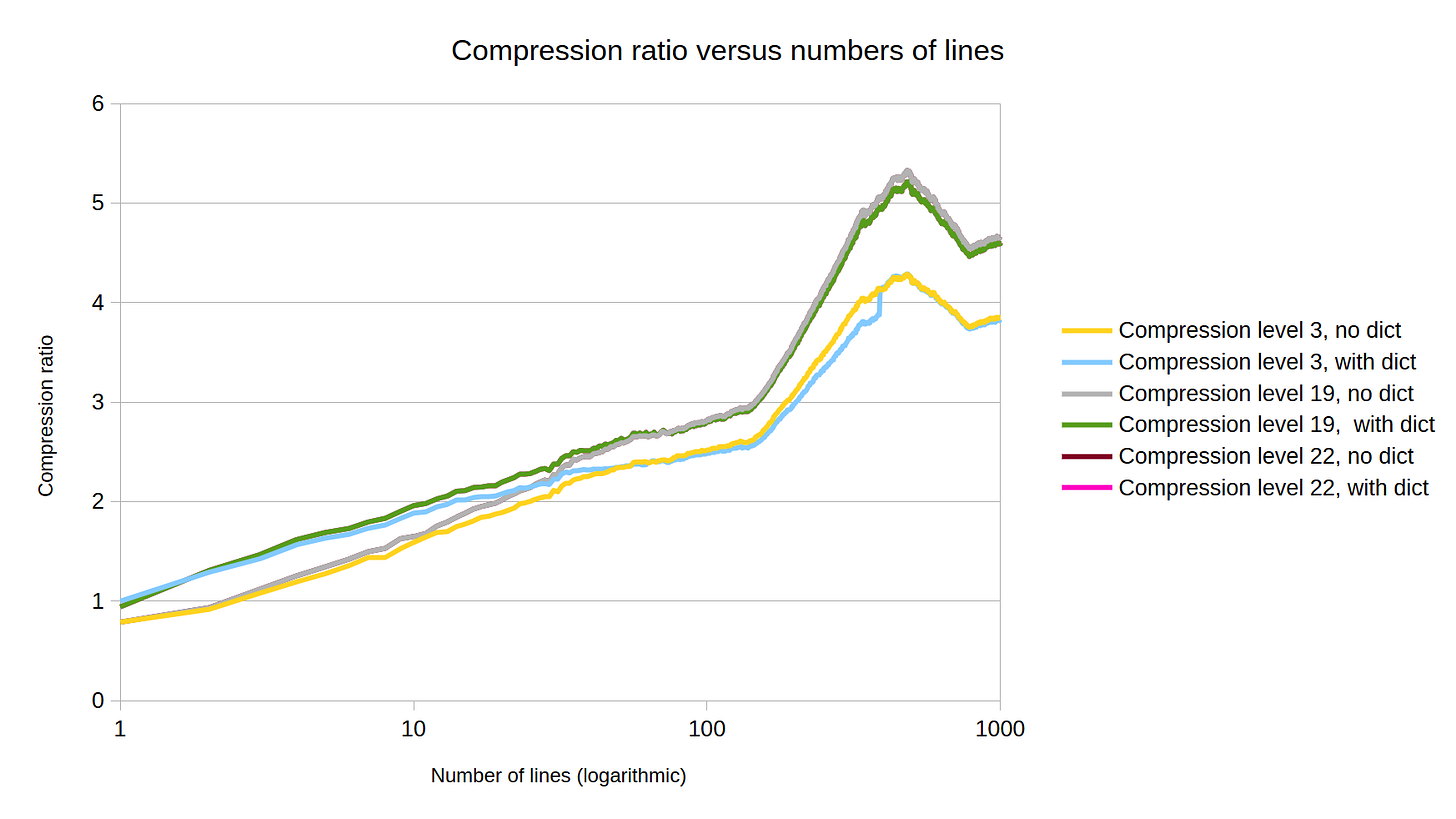
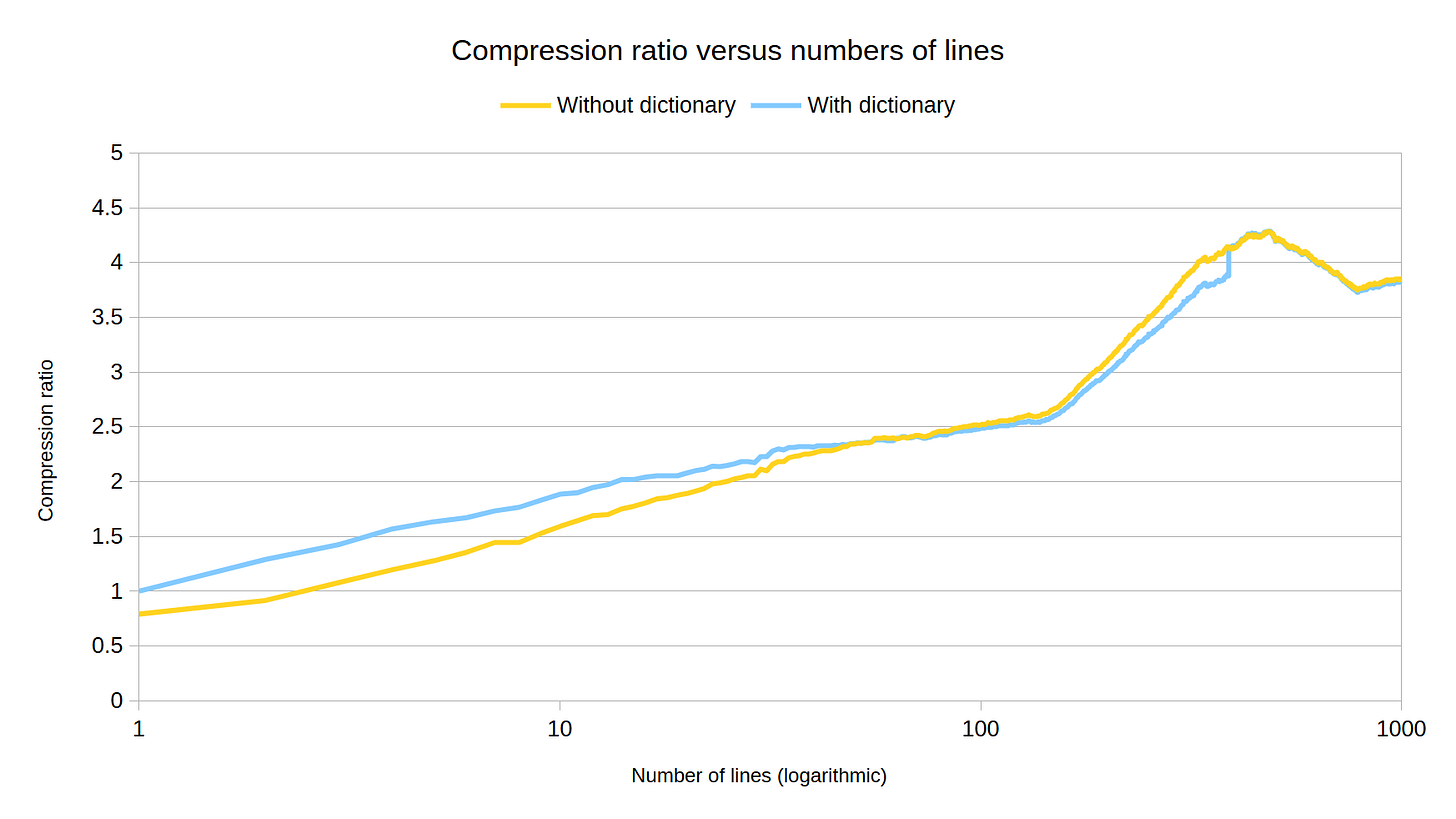
This can help us make a judgement call on where compression is useful, and when to bring in a dictionary. A more comprehensive test would repeat each length with random samples and take averages to account for any oddities in the test data, but this already gives us some sensible rules of thumb:
-
Below 3 or 4 messages, non-dictionary compression is counter productive
-
Dictionary-aided compression has a clear benefit up to about 10 messages, and then a diminishing return
-
At 30 messages, the difference is tiny (within 5%)
-
At 40 samples, the difference is negligible (within 1%)
What about tuning the compressor?
zstd, as with various other compression tools, lets us tune how much effort to put into compressing.
At the default compression level (level 3), compression is pretty fast - on my laptop the 1000 samples with and without dictionaries were generated in about 7 seconds.
Compression levels go all the way up to 22, taking longer and using more memory to get squeeze out as much compression as possible.
We’ll modify the generate.sh script to take a compression size as a parameter, defaulted to 3 (which is zstd’s default):
set -euo pipefail
COMPRESSION=${1:-3}
FILE="data-${COMPRESSION}.csv"
# delete the file if it exists
rm "$FILE" || true
# Write the header
echo "lines,uncompressed (bytes), compressed (bytes), compressed with dictionary (bytes)" >> "$FILE"
# For numbers 1-1000
for ((i=1; i<=1000; i+=1)); do
# Calculate data for raw, compressed and compressed-with-dictionary
raw="$(head -n $i messages.txt | wc --bytes)"
comp="$(head -n $i messages.txt | zstd --ultra "-${COMPRESSION}" | wc --bytes)"
comp_dict="$(head -n $i messages.txt | zstd -D ./dictionary --ultra "-${COMPRESSION}" | wc --bytes)"
# Append line to the file
echo "$i,${raw},${comp},${comp_dict}" >> "$FILE"
done
Running the script, we can see execution takes a lot longer at higher levels:
time ./generate.sh 3
# real 0m16.758s
# user 0m12.090s
# sys 0m12.128s
time ./generate.sh 19
# real 1m49.619s
# user 0m46.667s
# sys 1m14.784s
time ./generate.sh 22
# real 9m36.983s
# user 1m29.573s
# sys 8m18.624s
That’s a 34x slowdown from levels 3 to 22! Let’s see if it’s made any difference in compression level:
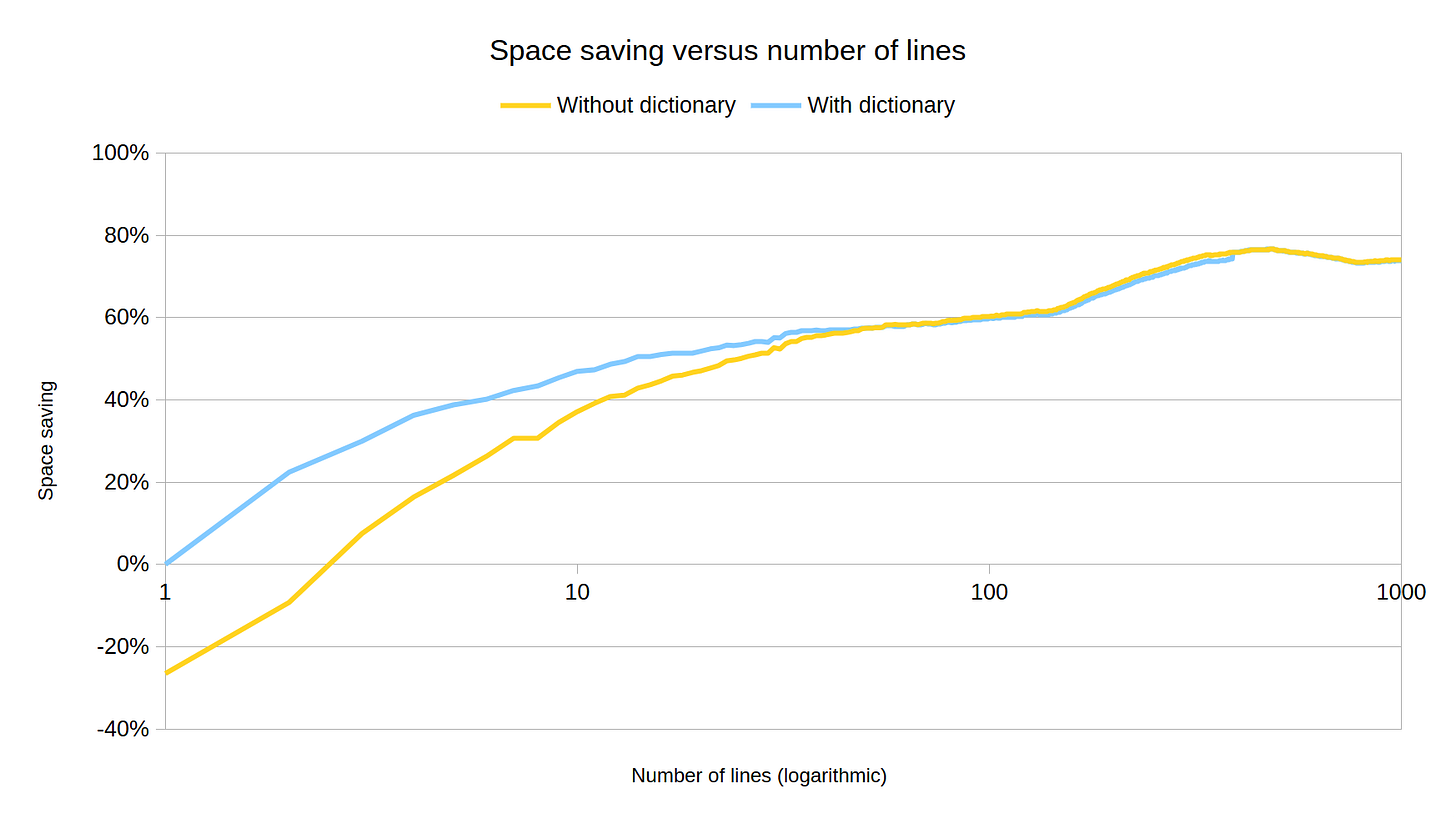
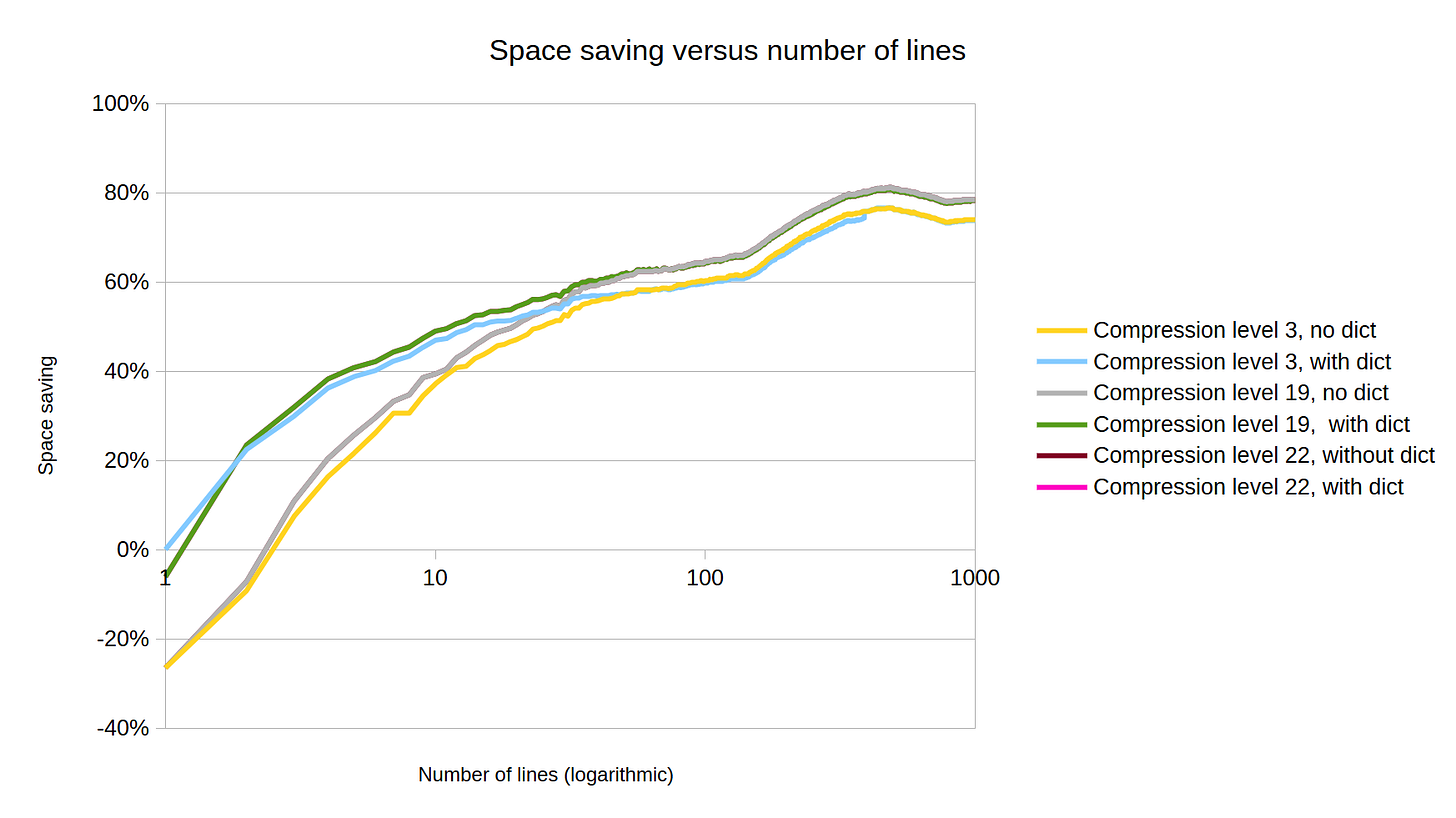
For a start, level 22 shows no improvement over 19, with the trend lines tracking so closely that 22 isn’t even visible as a separate line.
Comparing 3 to 19, we see that using a dictionary is still the greatest benefit for smaller numbers of lines. As greater numbers of lines (around 40-50, as we saw before), the compression begins to dominate and level 19 shows a visible improvement over level 3.
Of course, whether that improvement is worth the speed trade-off will depend on the specific usecase this would be deployed in.
Wrapping up
We’ve had a play with zstd and seen how building a custom dictionary can bring a marked benefit in compressing smaller strings.
We’ve also seen the importance of testing and measuring - having done that testing, we can not only decide what strategy to take now, we can also make sure we change strategies down the line if circumstances change.
For example, if we’re initially only compressing a small number of strings at a time, we might choose to build and maintain a dictionary, but if something else changes that means we’re now batching up larger blocks of data, we know that we can get rid of the whole dictionary mechanism.
If we were really dedicated, we’d also test other compression algorithms like gzip or bzip2 and see how they fare against our data.
Next article we’ll look at writing a custom compressor - see you then!