In my previous post, I compared the benefits of using a generic off-the-shelf compressor, with writing a custom compressor.
Now that we’ve played around with zstd and seen how it behaves at compressing varying volumes of AIS strings, it would be instructive to take a closer look at the structure of AIS strings and whether there’s any ‘wasted space’ we can take advantage of.
A quick primer on AIS sentences
With the help of this AIVDM/AIVDO decoding article from the gpsd project, let’s take a look at two example messages from the nmea sample data set we looked at in the last article.
!AIVDM,1,1,,A,13HOI:0P0000VOHLCnHQKwvL05Ip,0*23
!AIVDM,2,1,9,B,53nFBv01SJ<thHp6220H4heHTf2222222222221?50:454o<`9QSlUDp,0*09
!AIVDM,2,2,9,B,888888888888880,2*2E
An AIS sentence has a maxium of 82 bytes. If a message needs to be longer than that, it’ll be split over multiple sentences (‘fragments’) where each sentence contains:
-
A shared ‘message ID’ to match up which fragments go together
-
A count of how many fragments are in the message
-
A counter of which position a particular fragment occupies in the message
Here are the examples again, this time annotated with what the different segments represent:
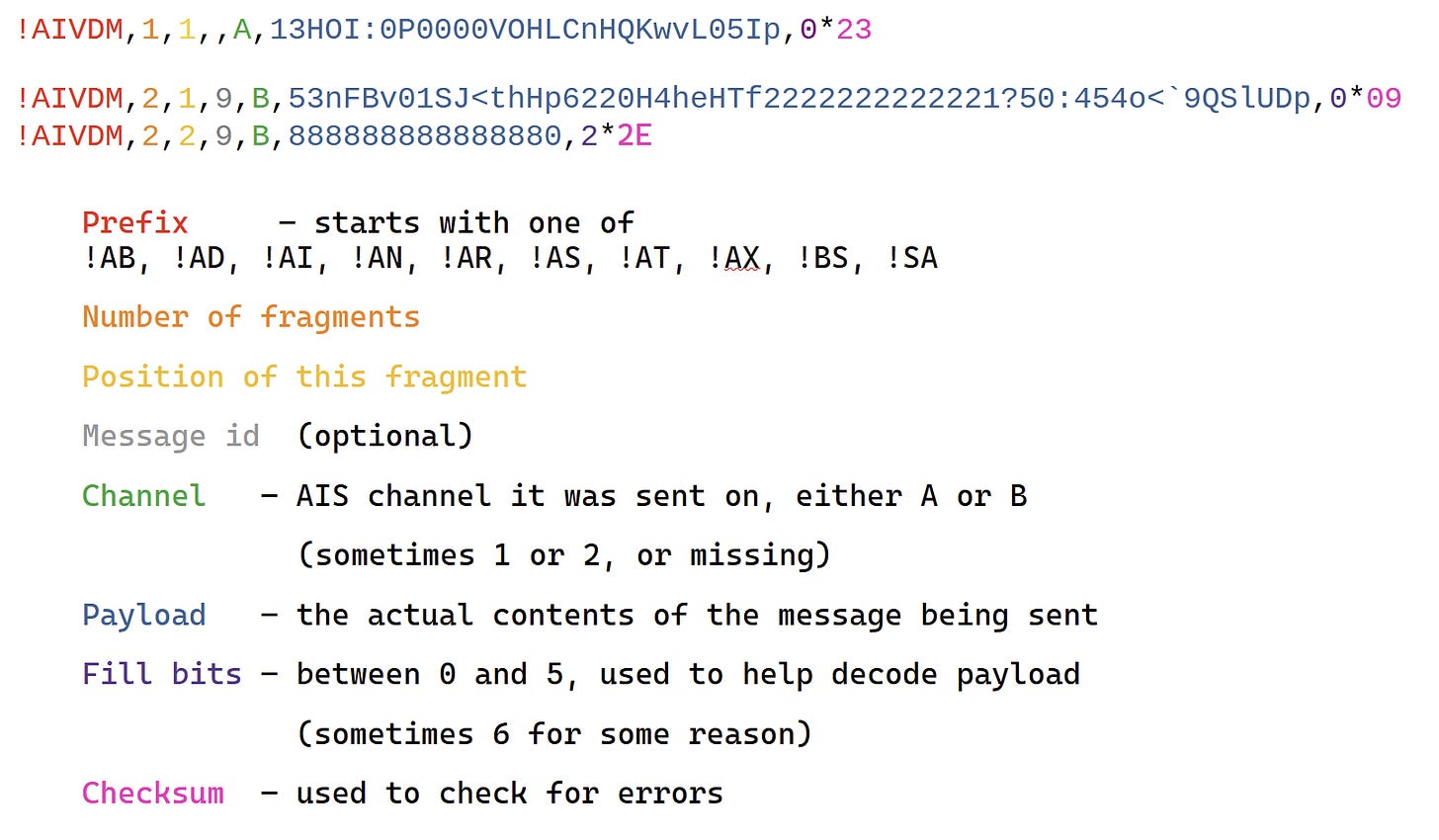
Most of the sections are separated by a comma, except for the final checksum which is preceded by an asterisk.
Knowing this, we can split the message in two:
-
Metadata:
-
Prefix
-
Number of fragments
-
Fragment position
-
Message ID
-
Channel
-
Fill bits
-
Checksum
-
-
Payload (the actual contents)
Let’s have a look at these in turn
Metadata
Let’s have a look at the number of possible values:
-
Prefix: 10 options (AI, AD, …)
-
Number of fragments: see below
-
Fragment position: see below
-
Message ID: 11 (0-9 or unspecified)
-
Channel: 5 (A, B, 1, 2 or missing)
-
Fill bits: 7 (0-6 inclusive)
-
Checksum1: 256 (2 hexadecimal characters)
For the ‘number of fragments’ entry, it’s not immediately clear how large these numbers can be and therefore how much we can compact them. A scan of the NMEA data sample shows message sizes of up to 4 fragments, but nothing I’ve seen guarantees this.
One option is to come up with the following scheme:
-
Be strict in the number of fragments (and various other properties)
-
If something fails our checks, send it as a raw string (without compression)
-
Use a single additional bit to distinguish ‘encoded’ from ‘unencoded’
The hope with this scheme is that the number of strings that fail our checks is likely to be very low, so even though the unencoded form is much longer, the effect on the overall data rate would be negligible.
That gives us
-
Encoded marker: 2 options (on/off)
-
Prefix: 10
-
Number of fragments: 4 (1-4)
-
Fragment position: 4 (1-4)
-
Message ID: 11 (0-9 or unspecified)
-
Channel: 5 (A, B, 1, 2 or missing)
-
Fill bits: 7 (0-6 inclusive)
-
Checksum: 256 (2 hexadecimal characters)
This gives us
2*10*4*4*11*5*7*256 = 31,539,200
different possibilities, or just under 25 bits2
The conversion between the unpacked form of this metadata and this tightly compressed 25-bit output is likely to be inefficient.
A more efficient but slightly less tightly-packed scheme is to allocate specific bits in byte to specific fields, so that sections can be unpacked independently by looking at specific bit patterns. Each field will have to be rounded up to the next power of two to indicate the number of bits it occupies. For example:
This scheme gets us down to a very reasonable 4 bytes - much smaller than the 21 characters/bytes used for metadata and separators in the original string!
Taking stock
We’ve managed a 5x compression in metadata by encoding the data into individual bits. That sounds great, right?
Unfortunately, metadata is only part of the message - the rest is the payload. Looking again at the sample NMEA data, the metadata takes up approximated 1/2 to 1/3 of the overall message, so the 5x compression of the metadata comes out to only 1.4-1.7x compression of the overall message - great, but certainly not groundbreaking!
Compressing the payload
So we’ve managed to compress the metadata down to a few bytes. What about the payload?
Another read of the AIVDM/AIVDO decoding article we looked at earlier shows the following:
The data payload is an ASCII-encoded bit vector. Each character represents six bits of data. […]
[…] the valid ASCII characters for this encoding begin with “0” (64) and end with “w” (87); however, the intermediate range “X” (88) to “\_” (95) is not used.
In effect, each character is taking up 8 bytes of data, but only represents 6 bytes. A good starting point would be to get rid of that ASCII encoding and work in terms of the original bytes, for a ‘free’ 25% reduction!
The schema will look something like the following:
-
Group the input ASCII into groups of 4 (although the final group might have less)
-
In each group:
-
Covert the ASCII characters into their respective 6-bit patterns
-
Concatenate the 6-bit patterns into a single 24-bit pattern
-
Split the 24-bit pattern into 3 byte patterns
-
This is a bit much for a bash script, so instead we can write it as a a Rust module (click on the caption for the full link).
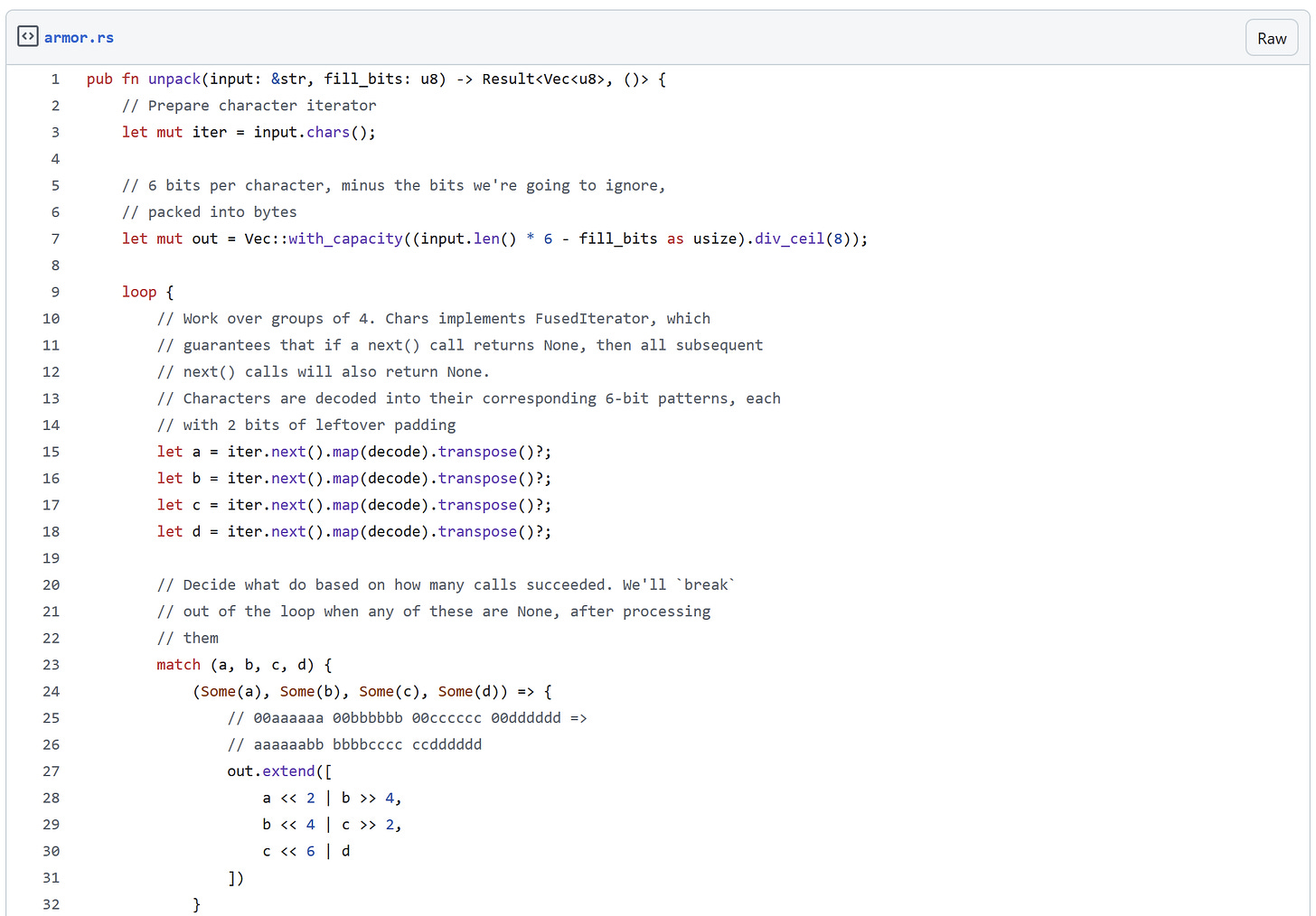
Writing the inverse method ends up being a lot of bit-manipulating, and in adding some round-trip tests we discover that the garbage bits at the end of AIS strings aren’t always 0, so if we want to preserve exact data we need to store those in our metadata as well. The code is a bit too long to copy here, but can be see in this PR.
Keen observers will note that there’s a couple of edge cases this explicitly doesn’t handle:
-
Very short messages (less than 3 bytes of payload)
-
Messages with a
fill_bitsvalue of 6 (not allowed according to the spec, but seen in thenmea-samplefile we’re using).
To handle these, we’ll fall back on the scheme we discussed earlier with message IDs - be strict in what we parse and compact, and fall back on sending the raw string instead for the rare instance that a message doesn’t match what we expect.
Anyway, barring these messages, we can successfully encode and decode the rest of the nmea-sample dataset, with all but 75 of the 85194 examples passing. That should be infrequently enough for our ‘fallback’ scheme to prove effective.
Time to move on!
Joining them together
We’ve now got a compression scheme for both the metadata and for the payload.
How do we pull together a bunch of messages into one contiguous chunk of data? We some way to distinguish:
-
The end of one AIS from the start of the next
-
Whether a message has been compacted or sent raw
-
How to split the metadata from the payload
-
When the stream of messages has ended, or whether it’s been interrupted
-
Ideally with some kind of error checking / spotting
We could continue to extend our binary datatype to handle all these, but we’ve been doing a lot of byte hacking here and I’m conscious of constantly reinventing the wheel.
Can we use a library to save ourselves some effort here?
Enter protobuf
Protobuf is a serialisation framework developed by Google, in which you define a .proto file defining your message structure, and use it to generate code bindings for your language.
It generates binary output, is widely tested and doesn’t rely on a single language, which make it a good default choice for this sort of thing.
It might not be the most 100% compact output (we still have to manually bitpack our metadata, and we’ll find it doesn’t handle splitting a metadata from
It’s also designed to make it easy to be forward-compatible, so we can add or remove fields down the line if we need to without breaking clients all at once.
Let’s define a simple protobuf file to define our encoded and unencoded messages:
// proto/ais/v1/spec.proto
edition = "2023";
package ais.v1;
message Encoded {
fixed64 metadata = 1;
bytes body = 2;
}
message Message {
oneof types {
string raw = 1;
Encoded encoded = 2;
}
}
In a nutshell, each Message item is either a ‘raw’ (i.e. just a string) or ‘encoded’ (metadata + body bytes value) value.
If we ever come up with a new definition, we can add it to the oneof value, enabling compatibility between old and new clients.
Hooking this up to our Rust code involves a small amount of boilerplate, which isn’t worth repeating here but can be seen in this PR. The best way to see the generated code is to run cargo doc --document-private-items --open and have a look around the generated docs:
Writing our conversions
Having generated the protobuf code, converting to and from bitstreams should be pretty mechanical.
First we need to define a new Metadata definition for the data we’re going to send over, to account for the new fill_bits and garbage bits we need to send over. We;’ll put this in our proto.rs:
bit_struct::bit_struct! {
// u8 is the base storage type. This can be any multiple of 8
pub struct Metadata(u64) {
talker: crate::sentence::TalkerID,
length: u8,
index: u8,
message_id: u8,
channel: crate::sentence::ChannelCode,
fill_bits: bit_struct::u3,
garbage_bits: u8,
checksum: u8,
}
}
We’ll then define our conversions - again, tedious to put in this article, but visible in this commit and and this commit.
Encoding multiple messages
One of the requirements I listed at the start of this section was to be able to tell where one message ends and another begins.
Unfortunately, protobuf doesn’t inherently support this - quoting from Techniques | Protocol Buffers Documentation:
If you want to write multiple messages to a single file or stream, it is up to you to keep track of where one message ends and the next begins. The Protocol Buffer wire format is not self-delimiting, so protocol buffer parsers cannot determine where a message ends on their own.
The easiest way to solve this problem is to write the size of each message before you write the message itself. When you read the messages back in, you read the size, then read the bytes into a separate buffer, then parse from that buffer.
While we can have a single protobuf message that carries multiple values, you have to know how many values you have up-front as that number will be encoded in the message.
There’s a few ways we could handle this:
-
Open a new connection per message (or set of messages) we want to send
-
Not great - for such small messages, the overhead of setting up the connection is likely to dominate the contents of the message
-
Also only works for connection-based output (like to a server), not to a file
-
-
Add a length prefix, as suggested in the document
-
Adds a bit of overhead per message
-
Hard to recover from - if some of the message gets garbled and we lose our length marker, we can’t work out what the next marker is without closing the connection and opening a new one, or simply erroring out.
-
-
Use a fixed marker to separate messages
-
Ideal if you can find a sequence of digits that you know won’t show up in your messages.
-
In our case, the messages contain arbitrary bytes in the payload, so we don’t have a sequence on hand.
- Instead, we have to use something like COBS to transform the output stream in a way that creates space for a marker. COBS manipulates the data in a way that converts the digits
{0…255}into{1…255}, therefore leaving0for the marker - at the cost of an ‘overhead byte’ to store the bits that have been pushed along. Read more about COBS.
- Instead, we have to use something like COBS to transform the output stream in a way that creates space for a marker. COBS manipulates the data in a way that converts the digits
-
Great for error recovery - if you find your stream gets garbled, you can scan forward until you find the next marker, throw away everything before it, and carry on from there.
-
Fortunately, the protobuf generator we’re using already implements the pattern described by the documentation (option 2), by providing a pair of functions:
write_length_delimited_to will write a length into the stream before writing the message, while read_bytes_to will first read the length N to find out how long the messages, then read the following N bytes from the stream, which we can parse as a message.
With that, we’re pretty much ready to start compressing!
Reading and writing
We should now have all the pieces to define our ‘compress’ and ‘decompress’ commands!
compress will take a series of lines, then
-
Try to parse each one as an AIS string
-
Convert it into a protobuf messages
-
Write the message length and message contents to its output
decompress will take its input, and:
-
Read a length
-
Use that to read the right number of bytes for the body
-
Parse those bytes as a protobuf message
-
Convert the protobuf message back into an AIS string
-
Write the string followed by a new line separate to its output
-
Repeat, reading a length…
// compress.rs
fn main() -> Result<(), Box<dyn std::error::Error>> {
let stdin = std::io::stdin().lock();
let mut stdout = std::io::stdout().lock();
let mut writer = protobuf::CodedOutputStream::new(&mut stdout);
for line in stdin.lines() {
let line = line?;
let message = line
.parse::<ais_compact::proto::spec::Message>()
.unwrap_or_else(|e| match e {});
message.write_length_delimited_to(&mut writer)?;
}
Ok(())
}
// decompress.rs
fn main() -> Result<(), Box<dyn std::error::Error>> {
let mut stdin = std::io::stdin().lock();
let mut reader = protobuf::CodedInputStream::from_buf_read(&mut stdin);
let mut stdout = std::io::stdout().lock();
while !reader.eof()? {
let message = reader.read_message::<ais_compact::proto::spec::Message>()?;
let nmea_message: ais_compact::sentence::Nmea = (&message).try_into()?;
writeln!(stdout, "{}", nmea_message)?;
}
Ok(())
}
Did it work?
Mostly!
Remember what we said about not handling two kinds of messages?
-
Invalid
fill_bitsvalue -
Too-short messages
In the first case, the compressor spots the error in encoding, refuses to compress it, and sends it as raw data, therefore passing through correctly.
In the second however the message is successfully compressed, but it’s the decompression that fails.
We need to be resilient to these kinds of failures - regardless of all our testing, there’s likely to be some edge case that causes a failure.
To defend against garbage or errors, we can following the following scheme - for each line:
-
Compress it on the client side
-
Decompress it, also on the client side
-
Check the result matches
-
Only then, send it off compressed - otherwise send it uncompressed
Taking this approach, we can preempt any errors, and bypass them - at the small cost of slightly more data for those erroring messages.
Let’s go ahead and implement it:
// compress.rs
fn check_roundtrip(
line: &str,
message: &ais_compact::proto::spec::Message,
) -> Result<(), Box<dyn std::error::Error>> {
let mut buf = Vec::new();
message.write_length_delimited_to_vec(&mut buf)?;
let mut input = CodedInputStream::from_bytes(&buf);
let result = input.read_message::<ais_compact::proto::spec::Message>()?;
if MessageWrapper(&result).to_string() != line {
return Err(anyhow::anyhow!("mismatch").into());
}
Ok(())
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
..
if let Err(_) = check_roundtrip(&line, &message) {
// Use a raw message instead
message = ais_compact::proto::spec::Message::from(line);
}
message.write_length_delimited_to(&mut writer)?;
..
}
Did it work? (this time)
Yes!
We can pass the nmea-sample data through the compression/decompression round trip and compare the differences:
cat nmea-sample | cargo run --bin compress | cargo run --bin decompress > nmea-output
diff --old-line-format='- %L' --new-line-format='+ %L' --unchanged-line-format='%L' nmea-sample nmea-output | diffstat
# 0 files changed
Did it compress?
Yes!
head -n 1 ./nmea-sample | wc --bytes
# 48
head -n 1 ./nmea-sample | cargo run --bin compress | wc --bytes
# 35
cat ./nmea-sample | wc --bytes
# 4151281
cat ./nmea-sample | cargo run --bin compress | wc --bytes
# 3025771
We get roughly a 1.4x compression ratio (or a roughly 29% saving in space), but unlike zstd in the previous article, it works all the way down to a single line - I’d say that’s pretty good result!
We’re not doing any ‘advanced’ compression here - all we’re doing is compacting the individual strings, rather than taking advantage of patterns across strings. We could certainly come up with some other techniques to further compress common patterns.
Let’s map that against the zstd results from the last article, for lines up to 10:
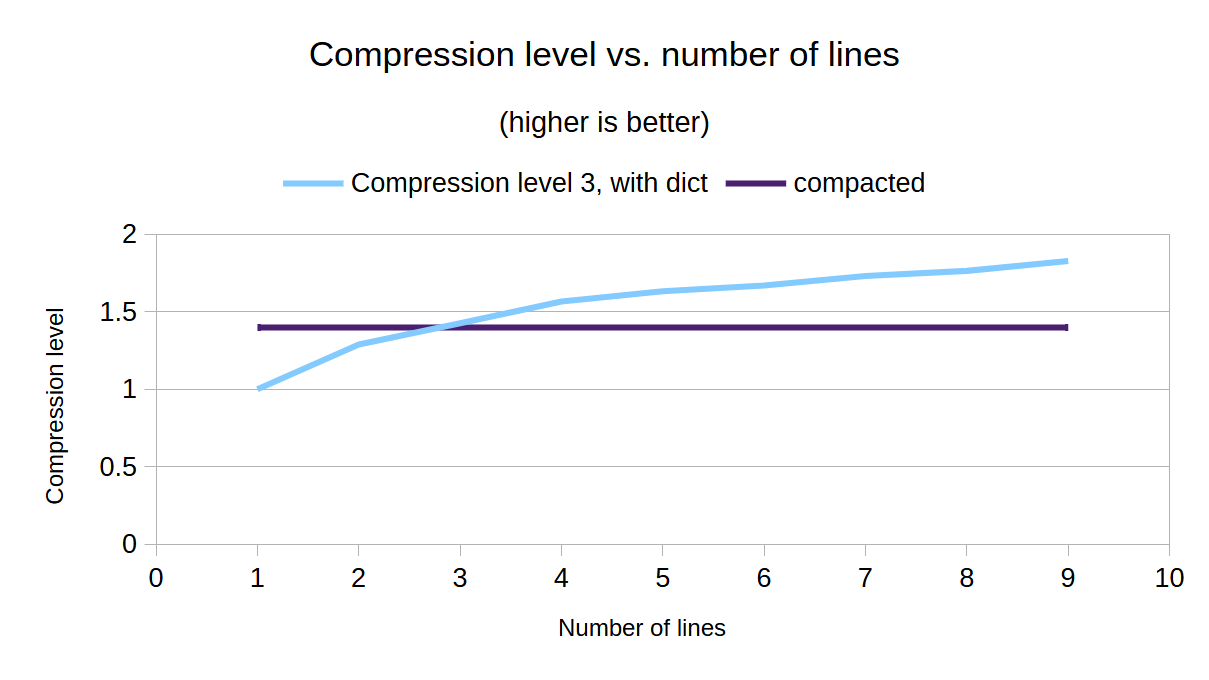
This gives us another rule of thumb to add to our results from the last article:
-
For sending one or two messages at a time, for example if we wanted to stream results in real-time, better to compact the message for 29% boost
-
For larger blocks of text, for example if we were saving up results and sending them in one go,
zstdwould be the way to go.
Next article, we’ll look at how we can make use of this. See you then!
Footnotes
[1] Strictly speaking we could drop the checksum, and recompute it at the other end when we convert the data back into a string. However, it provides a useful sense-check at the other end - if the compressor guarantees that it’s checked the checksum before sending, and the decompressor outputs a string with an invalid checksum, we can then spot that’s something gone wrong and do something sensible - raise an alert, close and re-establish the connection, etc.
[2] We can cheat a bit to get it under 24 bits - and therefore 3 bytes - by using the fact that when the encoding marker is set none of the other properties matter. We could therefore encode the rest of the properties, pick an unused bit pattern, and declare that to be the encoding pattern. In more formal terms this is a union rather than product join, so the calculation is 1 + 10*4*4*11*5*7*256 = 15,769,601.